Create the Lambda Function
Time Estimate: 10 - 15 minutes
In this section you will create the SQS Processor Lambda function.
Make sure you are in N. Virginia region. Look for the Lambda service in the AWS Management console and click on the highlighted result to access the service.
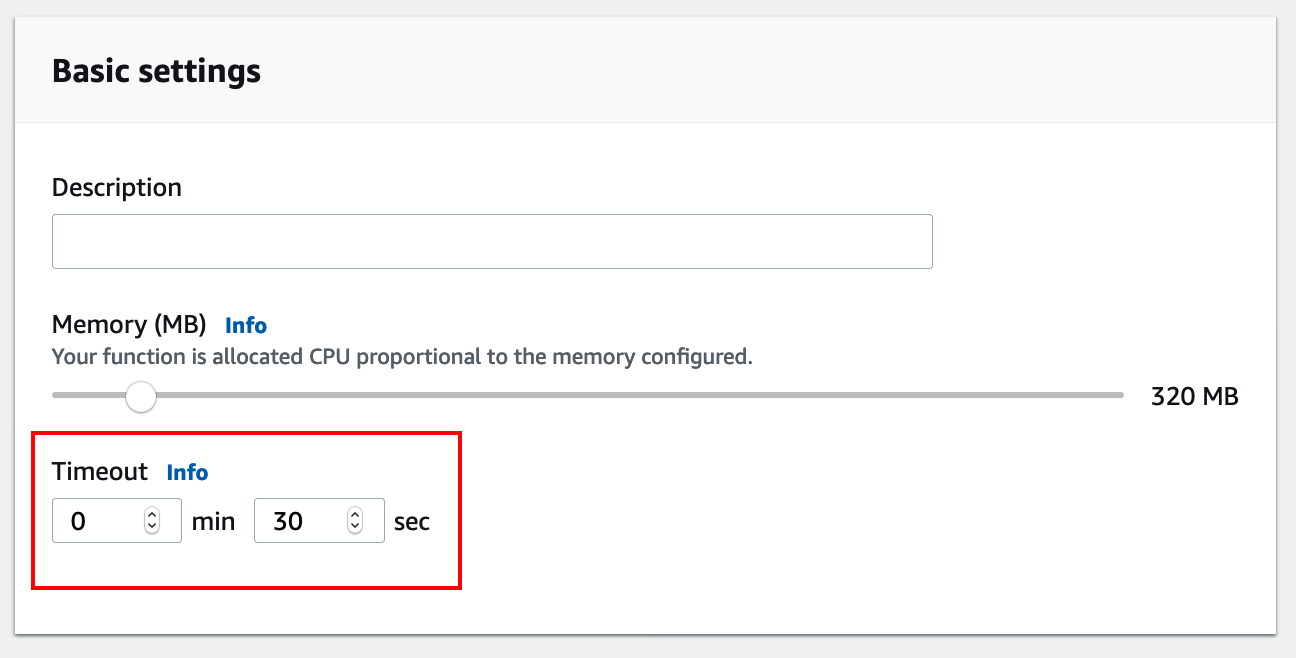
Follow the same steps as previously. Select the python runtime as shown below and configure the execution role to be the IAM role that that was created with CloudFormation when you were setting up the project. Click Create function.
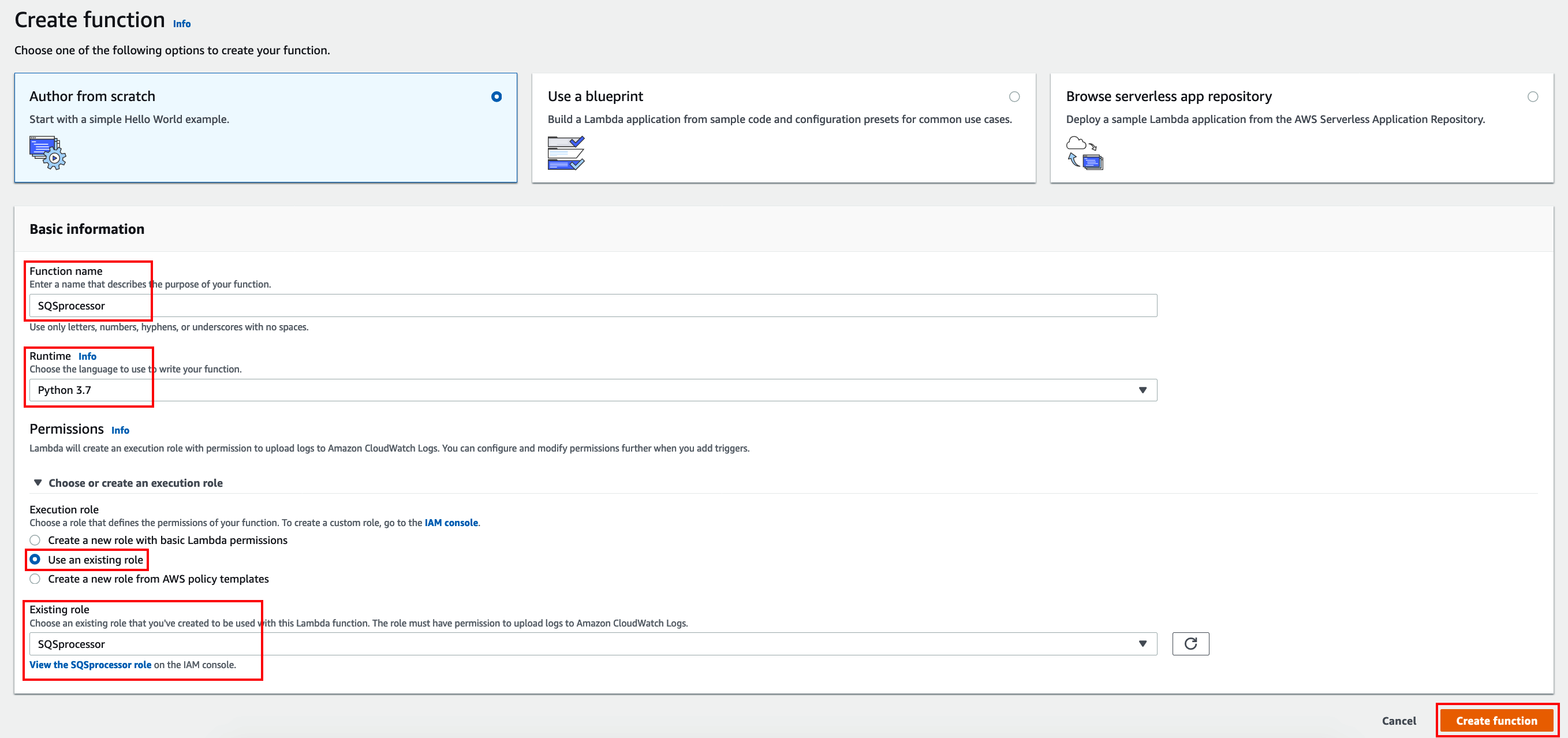
Copy the code below. The code will pick up a message in the Sync SQS queue, call Textract to process a document and then update the DynamoDB Documents and Outputs table as soon as a document has been processed.
import boto3
from decimal import Decimal
import json
import os
from helper import AwsHelper, S3Helper, DynamoDBHelper
from og import OutputGenerator
import datastore
def callTextract(bucketName, objectName, detectText, detectForms, detectTables):
textract = AwsHelper().getClient('textract')
if(not detectForms and not detectTables):
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': bucketName,
'Name': objectName
}
}
)
else:
features = []
if(detectTables):
features.append("TABLES")
if(detectForms):
features.append("FORMS")
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': bucketName,
'Name': objectName
}
},
FeatureTypes=features
)
return response
def processImage(documentId, features, bucketName, objectName, outputTableName, documentsTableName):
detectText = "Text" in features
detectForms = "Forms" in features
detectTables = "Tables" in features
response = callTextract(bucketName, objectName, detectText, detectForms, detectTables)
dynamodb = AwsHelper().getResource("dynamodb")
ddb = dynamodb.Table(outputTableName)
print("Generating output for DocumentId: {}".format(documentId))
opg = OutputGenerator(documentId, response, bucketName, objectName, detectForms, detectTables, ddb)
opg.run()
print("DocumentId: {}".format(documentId))
ds = datastore.DocumentStore(documentsTableName, outputTableName)
ds.markDocumentComplete(documentId)
# --------------- Main handler ------------------
def processRequest(request):
output = ""
print("request: {}".format(request))
bucketName = request['bucketName']
objectName = request['objectName']
features = request['features']
documentId = request['documentId']
outputTable = request['outputTable']
documentsTable = request['documentsTable']
documentsTable = request["documentsTable"]
if(documentId and bucketName and objectName and features):
print("DocumentId: {}, features: {}, Object: {}/{}".format(documentId, features, bucketName, objectName))
processImage(documentId, features, bucketName, objectName, outputTable, documentsTable)
output = "Document: {}, features: {}, Object: {}/{} processed.".format(documentId, features, bucketName, objectName)
print(output)
return {
'statusCode': 200,
'body': output
}
def lambda_handler(event, context):
print("event: {}".format(event))
message = json.loads(event['Records'][0]['body'])
print("Message: {}".format(message))
request = {}
request["documentId"] = message['documentId']
request["bucketName"] = message['bucketName']
request["objectName"] = message['objectName']
request["features"] = message['features']
request["outputTable"] = os.environ['OUTPUT_TABLE']
request["documentsTable"] = os.environ['DOCUMENTS_TABLE']
return processRequest(request)#### Important code snippets in the Lambda function
* Below is where we call the textract ***detect_document_text*** API. This API call will return the raw text in an image in a JSON structure.
```python
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': bucketName,
'Name': objectName
}
}
```
* Below if we detect more complicated structures like forms and tables we call the ***analyze_document*** API. This API call will return the raw text and the also the relationships between detected text.
```python
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': bucketName,
'Name': objectName
}
}
```
Paste the code as shown below and click Save.
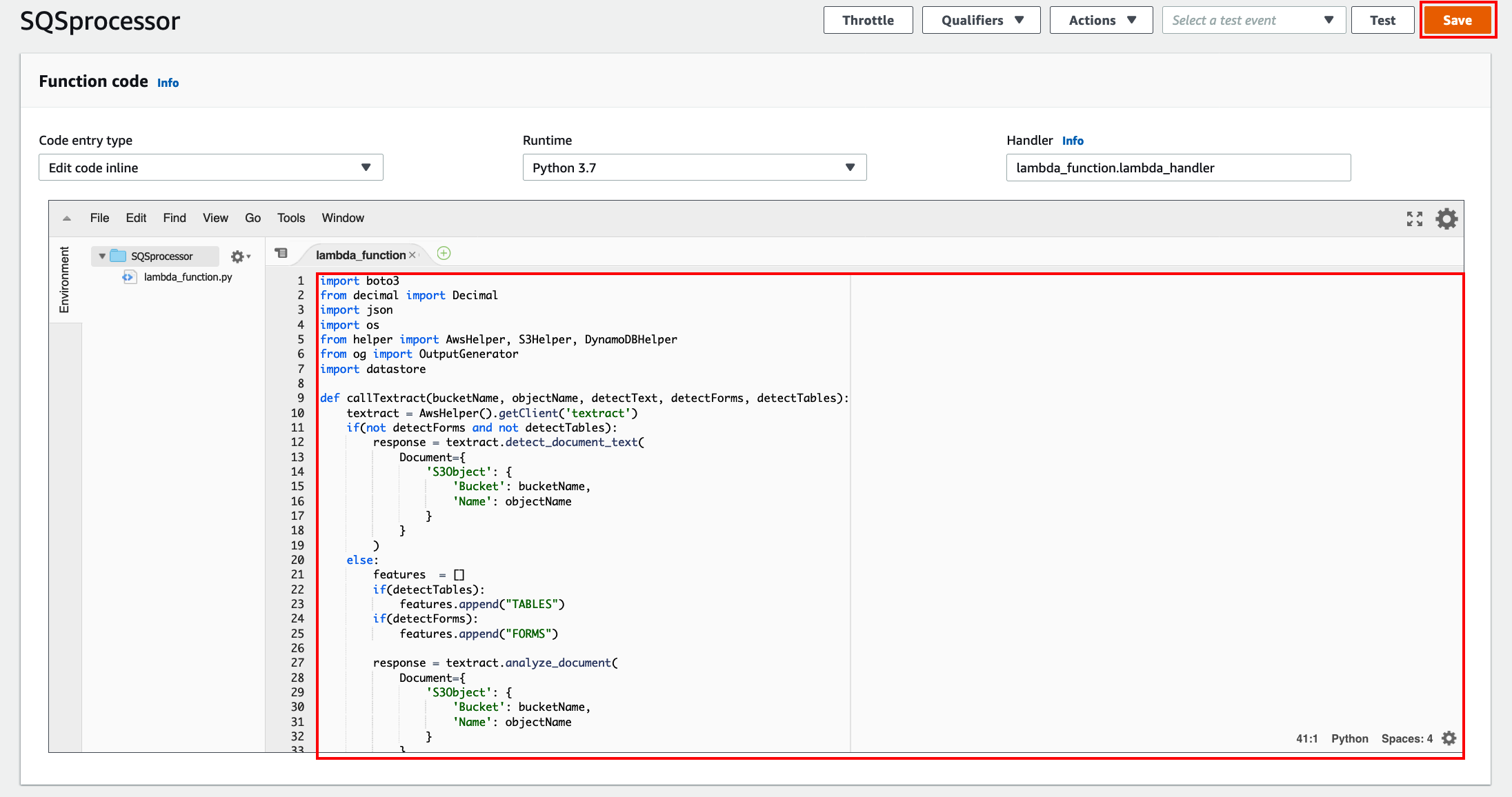
We need to configure some enviroment variables in order for our Lambda fucntion to be able to identify the DynamoDB tables. The enviroment variables we are going to configure are:
DOCUMENTS_TABLE -> Documents table name OUTPUT_TABLE -> Ouputs table name
Configure those as shown below. Then click Save.
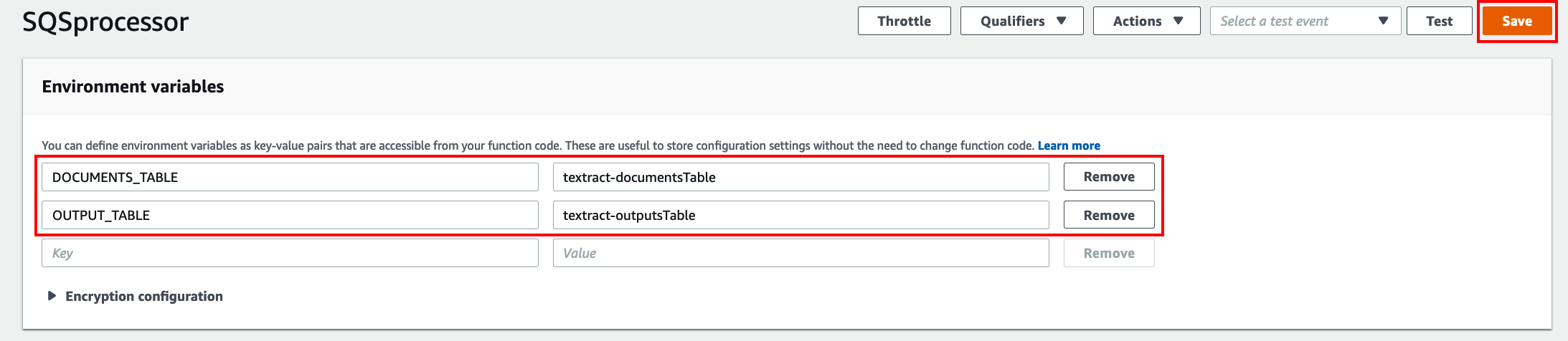
Increase the time out of the Lambda function as shown below. This is to ensure the Lambda has enough time to finish processing before it times out. Then click Save.