Workshop Architecture
Workshop high level architecture
This reference architecture shows how you can extract text and data from documents at scale using Amazon Textract. The architecture is serverless, highly available and highly scalable.
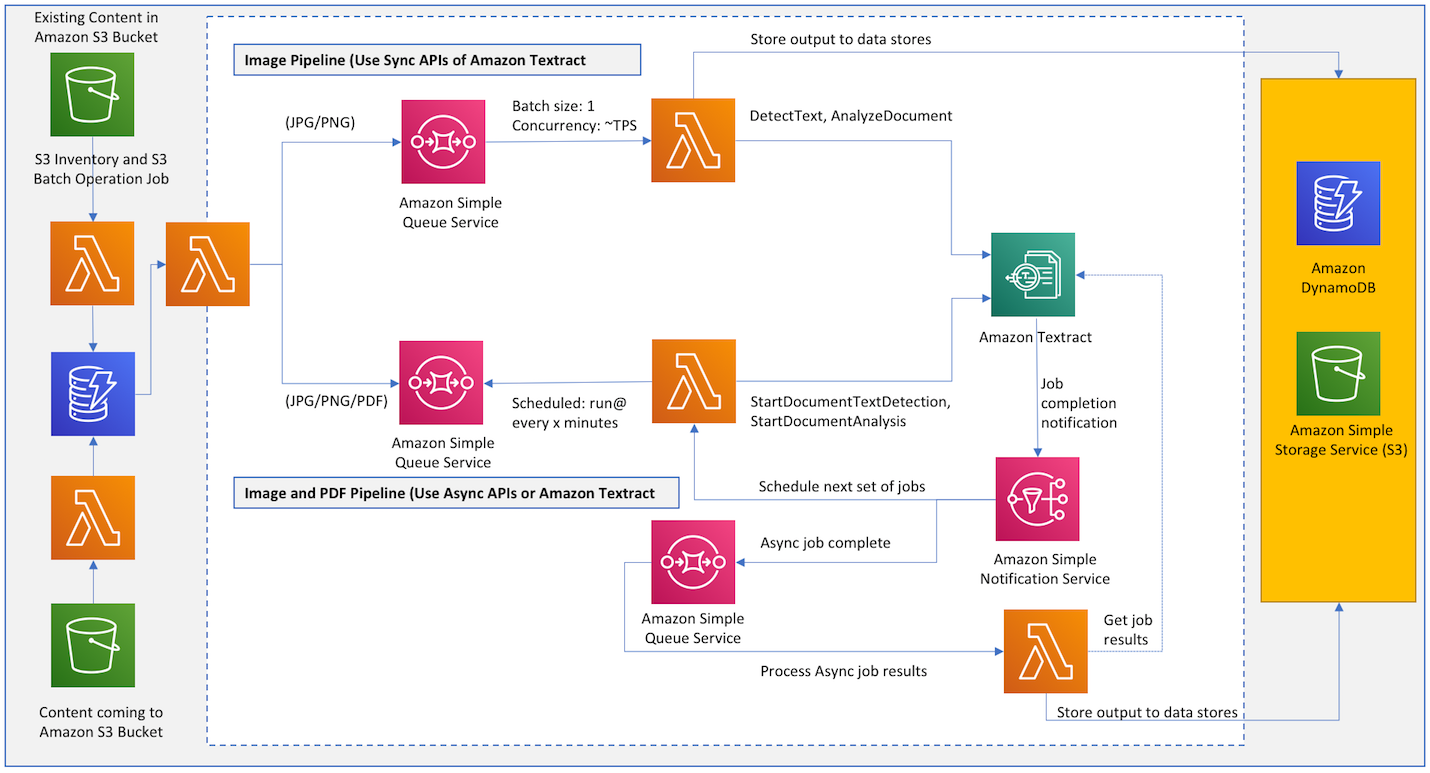
Image pipeline (Use Sync APIs of Amazon Textract)
- The process starts as a message is sent to an Amazon SQS queue to analyze a document.
- A Lambda function is invoked synchronously with an event that contains queue message.
- The Lambda function then calls Amazon Textract and stores the result in different datastores in this instance Amazon DynamoDB and Amazon S3.
- You control the throughput of your pipeline by controlling the batch size and Lambda concurrency.
Image and PDF pipeline (Use Async APIs of Amazon Textract)
- The process starts when a message is sent to an Amazon SQS queue to analyze a document.
- A job scheduler Lambda function runs at certain frequency for example every 5 minutes and poll for messages in the SQS queue.
- For each message in the queue it submits an Amazon Textract job to process the document and continue submitting these jobs until it reaches the maximum limit of concurrent jobs in your AWS account.
- As Amazon Textract is finished processing a document it sends a completion notification to an Amazon SNS topic.
- Amazon SNS then triggers the job scheduler Lambda function to start next set of Amazon Textract jobs.
- Amazon SNS also sends a message to an SQS queue which is then processed by a Lambda function to get results from Amazon Textract and store them in a relevant dataset to DynamoDB and S3.