Test the Asynchronous Pipeline
Time Estimate: 10 - 15 minutes
In this section you will test the asynchronous document processing pipeline that you deployed in the previous steps. You will simulate the processing of multiple documents that already exist in an Amazon S3 bucket. We will leverage S3 Batch operations to achieve the above.
What is S3 Batch operations?
Amazon S3 batch operations performs large-scale batch operations on Amazon S3 objects.
For more information, see https://docs.aws.amazon.com/AmazonS3/latest/user-guide/batch-ops.html.
Download the sample documents below (jpg/jpeg, png, pdf).
Go to the Amazon S3 bucket
textractpipeline-existingdocumentsbucketxxxxcreated by the CDK commands and upload the pdf document and images that you downloaded. The xxx at the end of thetextractpipeline-existingdocumentsbucketxxxxshould have been replaced with a random string in your AWS Account.Download, open the
inventory-test.csvfile and then replace thetextractpipeline-existingdocumentsbucketxxxxvalue with the actual Amazon S3 bucket name of Step 2 above where you uploaded the 3 documents (employmentapp.png, pdfdoc.pdf, twocolumn.jpg).Go to the Amazon S3 bucket
textractpipeline-inventoryandlogsxxxxxand upload the csvinventory-test.csvfile containing the list of document names you just uploaded to the buckettextractpipeline-existingdocumentsbucketxxxx. The CSV file should have two columns bucketName and objectName.Note: You can also use Amazon S3 Inventory to automatically generate a list of documents in your Amazon S3 bucket.
Go to Amazon S3 and click on Batch operations like below:
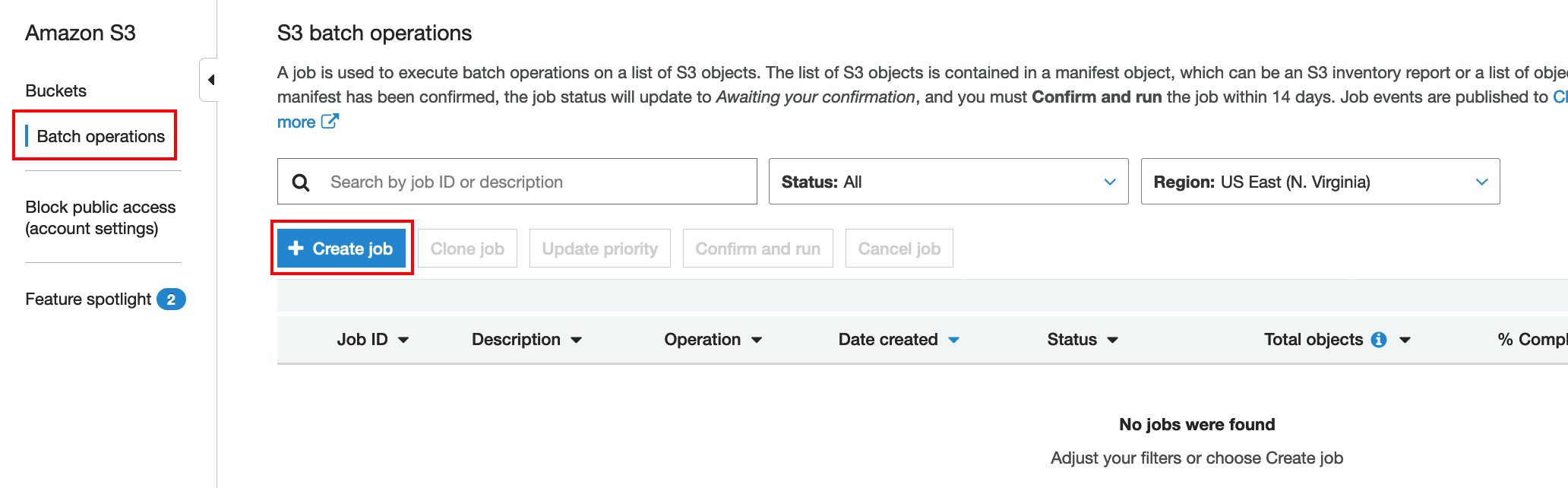
Select
CSVunder Mafifest format and under Path to manifest object navigate to yourinventory-test.csvfile like in the screen shot below. Then choose Next.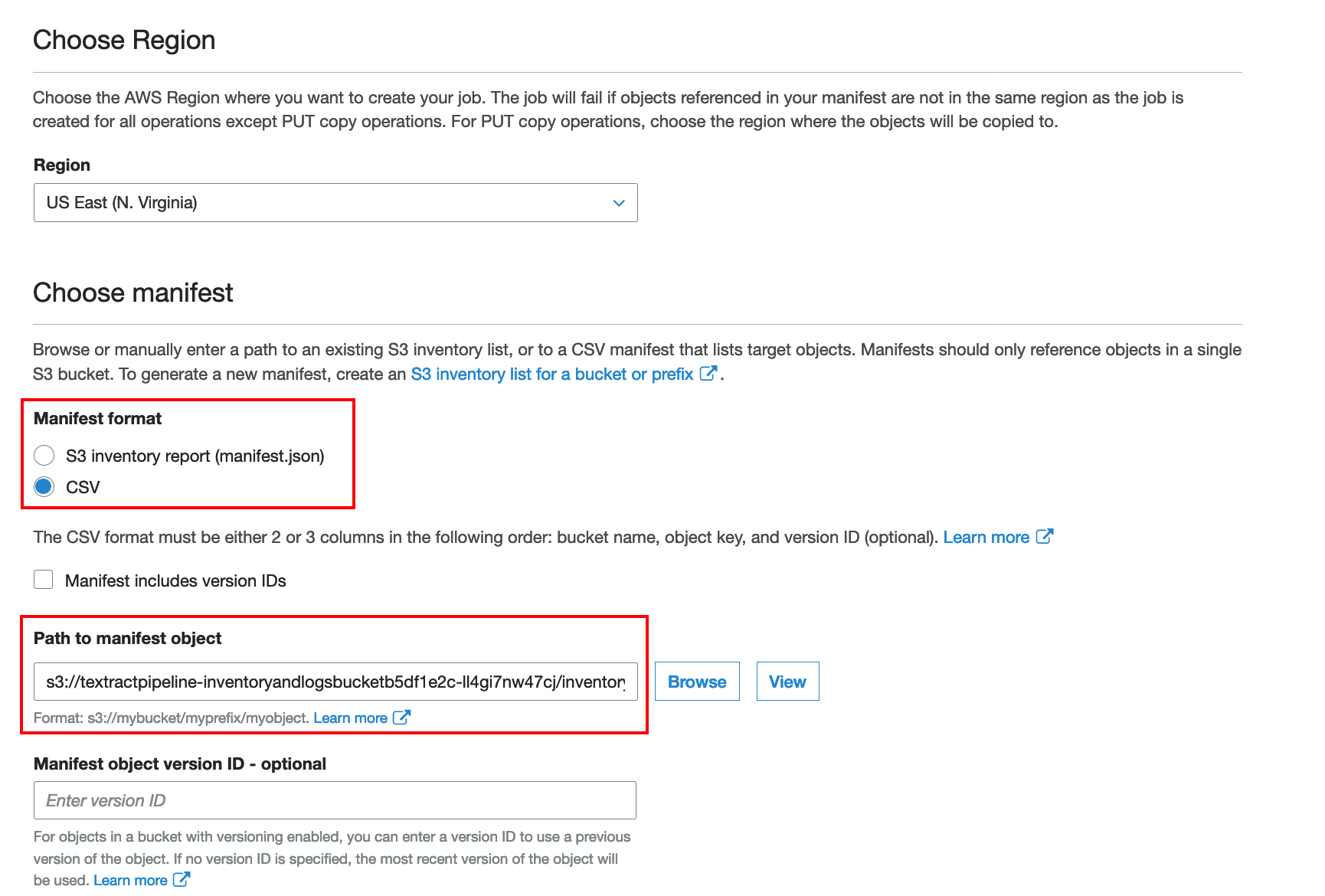
Under Operation choose
Invoke AWS Lambda functionand under Lambda function chooseTextractPipeline-S3BatchProcessorxxxxlike in the screen shot below. Then choose Next.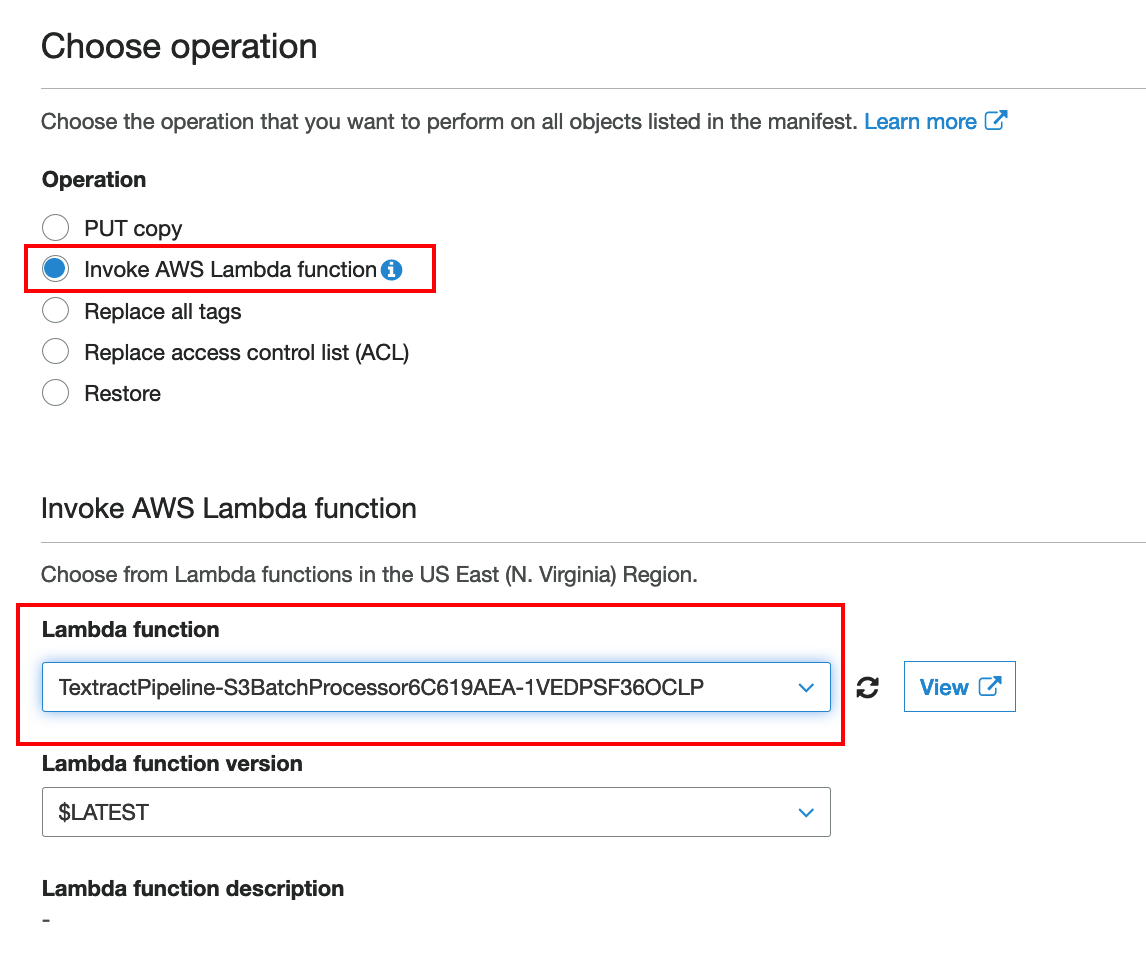
Untick the Generate completion report box and under Permissions to access the specified resources choose
Choose from existing IAM rolesand for IAM roleTextractPipeline-S3BatchOperationRolexxxxlike in the screen shot below. Then click Next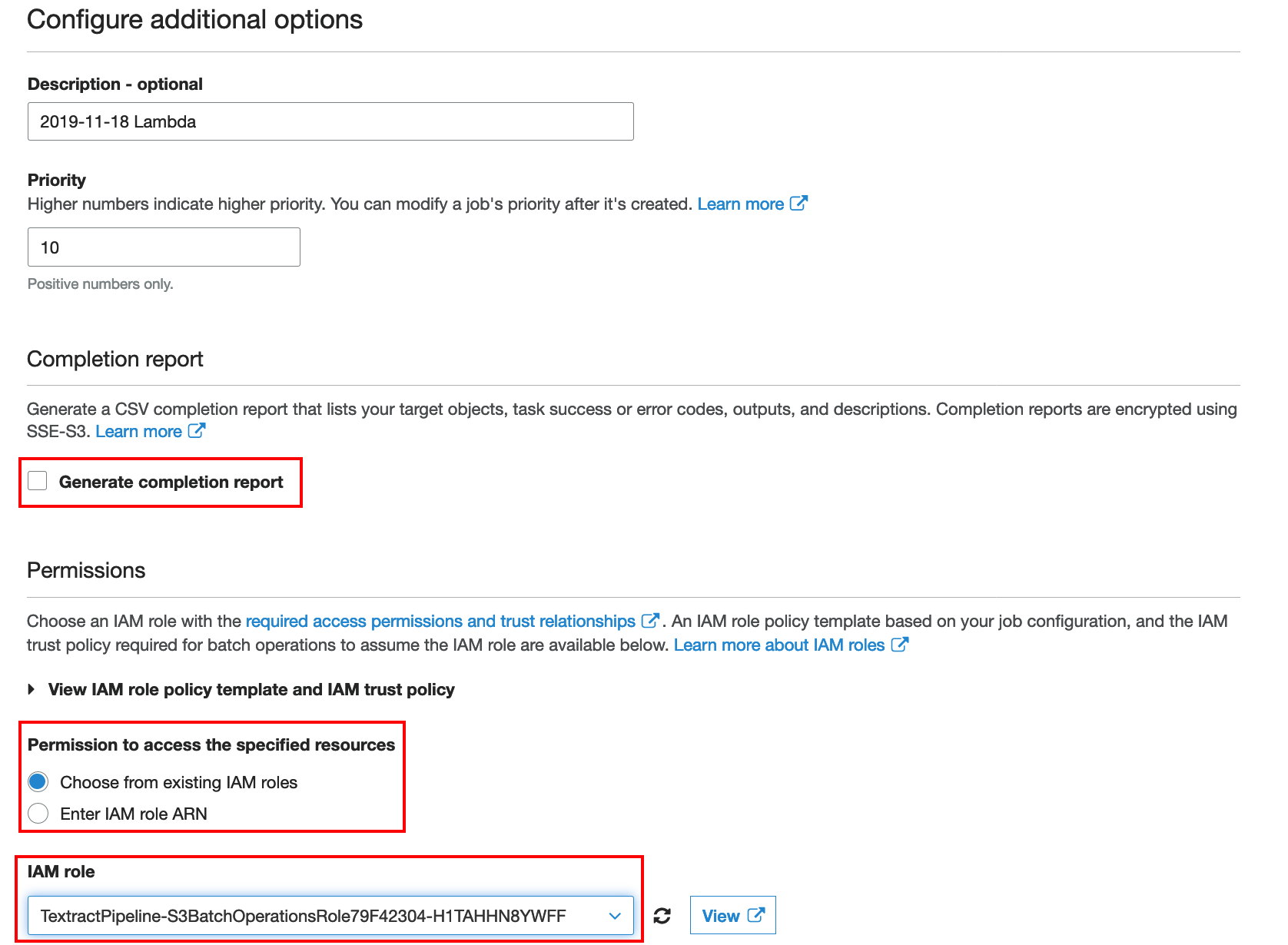
Review and click Create job.
You should see now a screen like below:
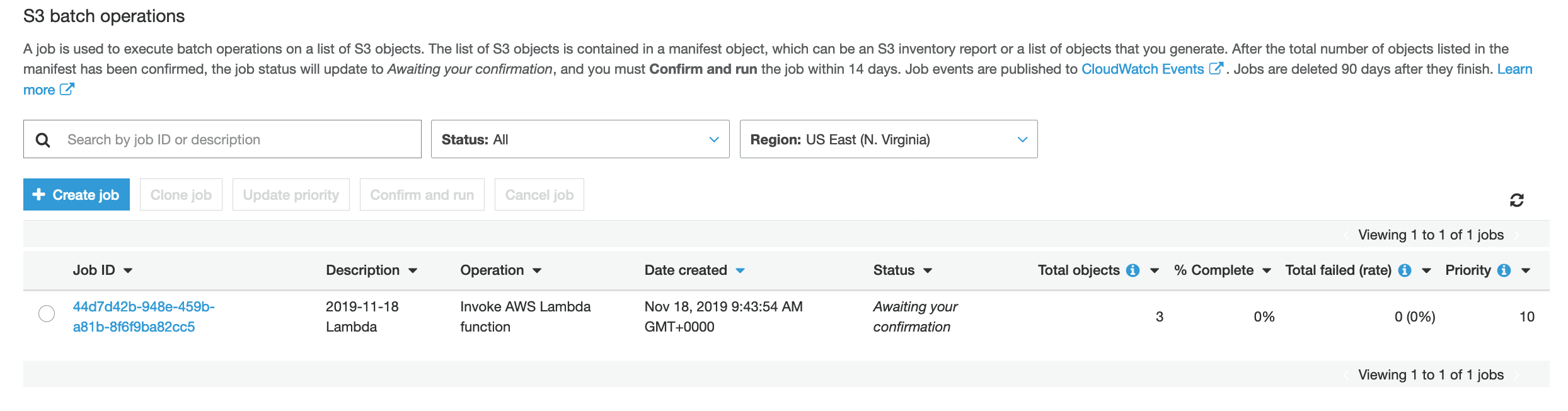
From Amazon S3 Batch operations page, click on the Job ID link for the job you just created.
Click Confirm and run and then Run job.
From S3 Batch operations page, click refresh to see the job status.
Go to Amazon S3 bucket
textractpipeline-existingdocumentsbucketxxxxand you should see output generated for documents in your list like in the screen shot below: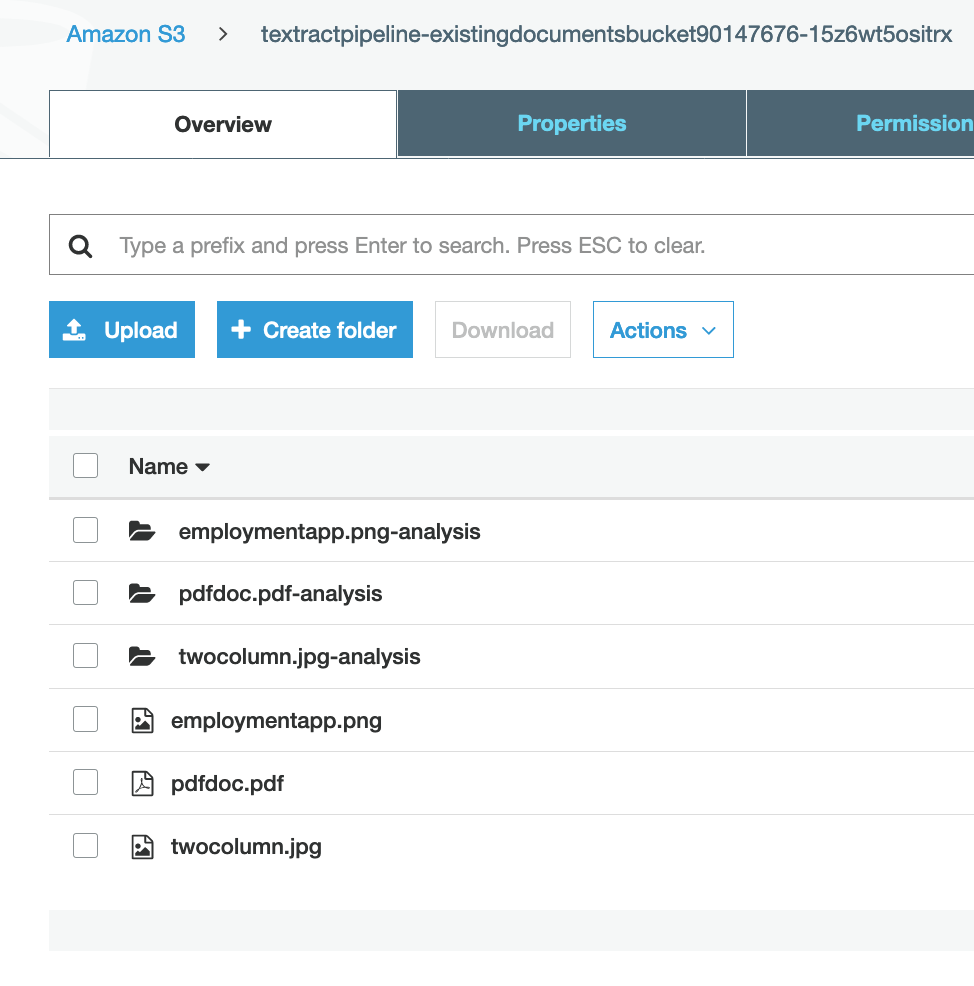
Congrats! You run the asynchronous document pipeline for 3 existing documents in your S3 bucket using S3 batch operations !!