Module 1 - Synchronous Processing
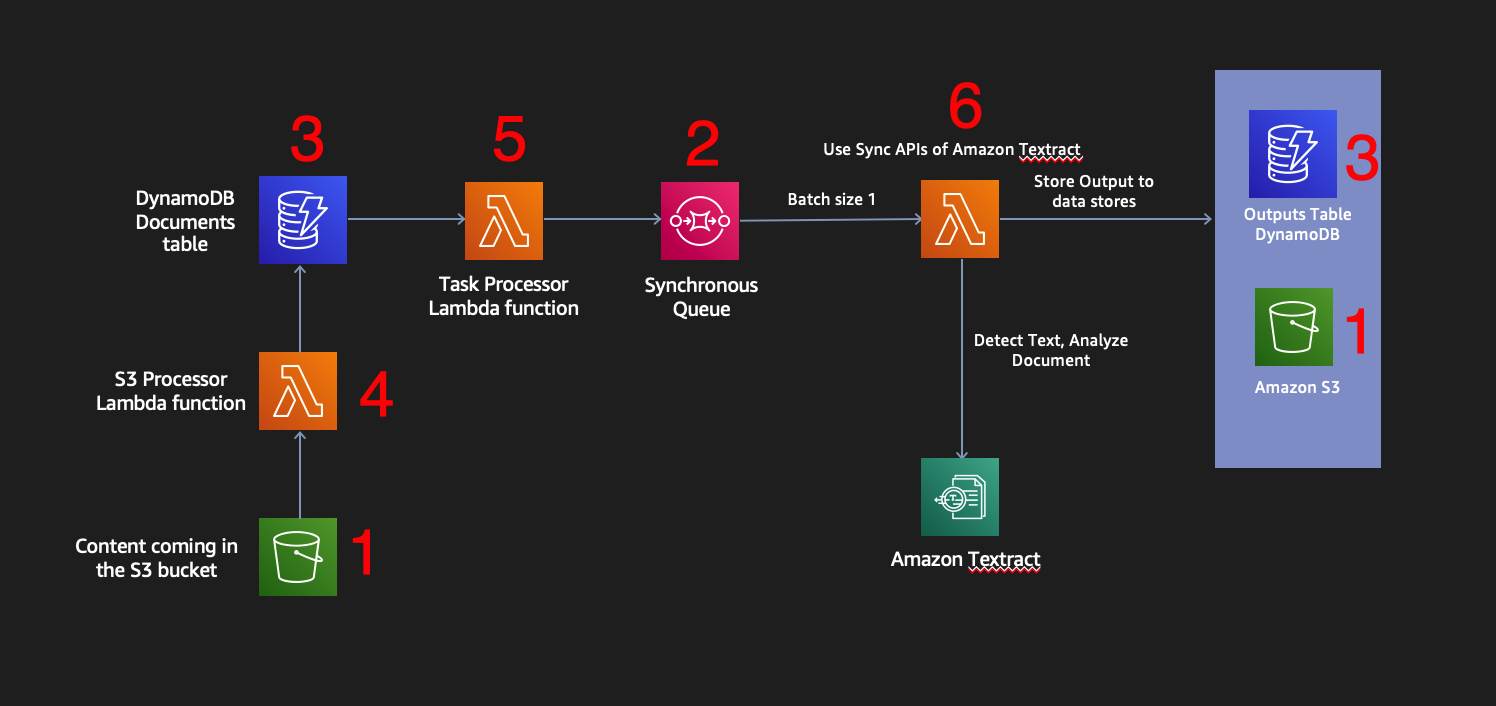
You are going to create the synchronous document processing pipeline in 6 steps:
You will create an S3 bucket to upload documents and store the results of processing.
You will create the synchronous processing SQS queue. As soon as a document is uploaded at the S3 bucket we will put a message in the queue.
You will create 2 DynamoDB tables. Those will store metadata for the uploaded processed documents.
You will create a Lambda function that will be triggered when a document is uploaded in the S3 bucket and create tasks in the Documents DynamoDB table.
You will create a Lambda function that will be triggered as soon as a task is created in the DynamoDB Documents table and will place a message in our synchronous SQS queue.
You will create a Lambda function that will process the uploaded document by picking up messages from the synchronous SQS queue and will call the synchronous Textract APIs.
You are going to test the pipeline by uploading an image to our S3 Bucket and then you will review the Outputs.
The architecture for Module 1 is below: